In a Hadoop cluster, how to contribute a limited/specific amount of storage as a slave to the cluster
Oct 19, 2020
Task 4.1

The Hadoop cluster is set up on the top of the AWS cloud. We configured namenode (master) as well as datanode (slave).

Created external harddisk (EBS) and attached it to the datanode (slave-1).
Why we had done this?
To contribute limited storage (if you want more storage then you can make a large hard disk) to the namenode. Also, it will be persistent after the reboot or crash or corrupt.

After attaching it to datanode we have to partition the external harddisk and then format it.
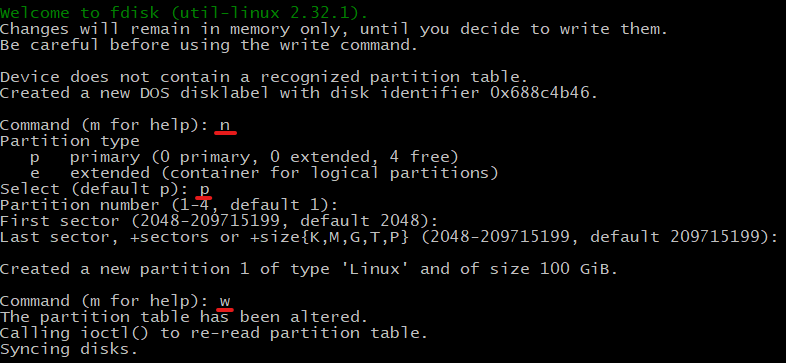
n for the new partition.
p for primary partition.
w to save the partition.
format the partition
mkfs.ext4 /dev/xvdf
--------------------------------------------------------------------create folder
mkdir datanode
--------------------------------------------------------------------mount the harddisk to the folder.
mount /dev/xvdf /datanode
--------------------------------------------------------------------Confirm the harddisk is attached or not.
df -h
start the datanode
hadoop-daemon.sh start datanode
--------------------------------------------------------------------
check cluser details
hadoop dfsadmin -report
Github





